
The Scalability Team has the goal of understanding
potential scaling bottlenecks in our application. We formed a year ago
with one person, and as of early 2020, we are made up of three backend
engineers, plus one site reliability engineer. We are a
sort of program team so we have a wide remit, and there's only one
similar team at GitLab: our sibling Delivery Team. All of
the backend engineers in the team (including me) came from
working on product development rather than infrastructure work.
We recently finished a project where we investigated our use of
Sidekiq and made various improvements. We decided to continue
the same approach of looking at services, and got started with our next
target of Redis. Here are some lessons we took away:
1. Don't lose sight of what matters most: impact
We chose to split our work on Redis into three phases:
- Visibility: increase visibility into the service.
- Triage: use our increased visibility to look for problems and
potential improvements, and triage those. - Knowledge sharing: share what we learned with the rest of the
Engineering department.
Iteration is crucial at GitLab, so much so that we have regular
Iteration Office Hours. On the surface, you could say that we were
iterating here: our issues were small and well-scoped and we were
delivering code to production regularly.
The problem, as it turned out, was that we were focused so heavily on
understanding the service, that we lost track of the results we were
trying to deliver. Our values hierarchy puts results at the top, but
we hadn't given the results enough attention. We are a small team that
needs to cover a wide area, and we need to deliver impactful changes.
There are some examples in our handbook – which we've added as
a result of this project – but we define impact as either having a
direct effect on the platform, our infrastructure, or our development
teams. That was what was missing here, because the impact was loaded
towards the very end of the project: largely in the knowledge sharing
section.
We spent a long time (several months) improving our visibility, which
definitely has a positive impact on our SREs who spend time
investigating incidents. But we could have delivered this value and more
in a shorter time period, if we had kept clear sights on the impact we
wanted to have.
2. Minimum viable change applies to scaling problems too
With that framing in mind, it's quite clear that we weren't iterating in
the best way. To use a famous example, it's like we'd started building a
car by building the wheels, then the chassis, etc. That takes a long
time to get something useful. We could have started by building a
skateboard. We didn't have a good sense of what a minimum viable change
was for our team, so we got it wrong.
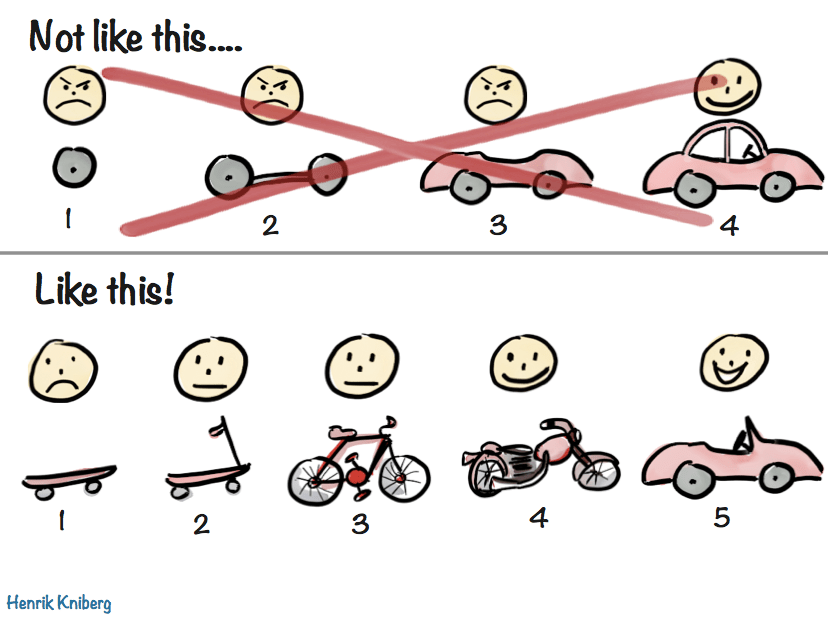
Illustration by Henrik Kniberg
What would a minimum viable change look like? When we worked on this project, we
covered several topics: adding Redis calls to our standard structured
logs, exposing slow log information, and so on. With hindsight, the best
way would probably be to slice the project differently. We could take
the three steps above (visibility, triage, knowledge sharing), but
consider them all to be necessary for a project on a single topic with a
tangible goal.
We did this, with all the impact at the end:
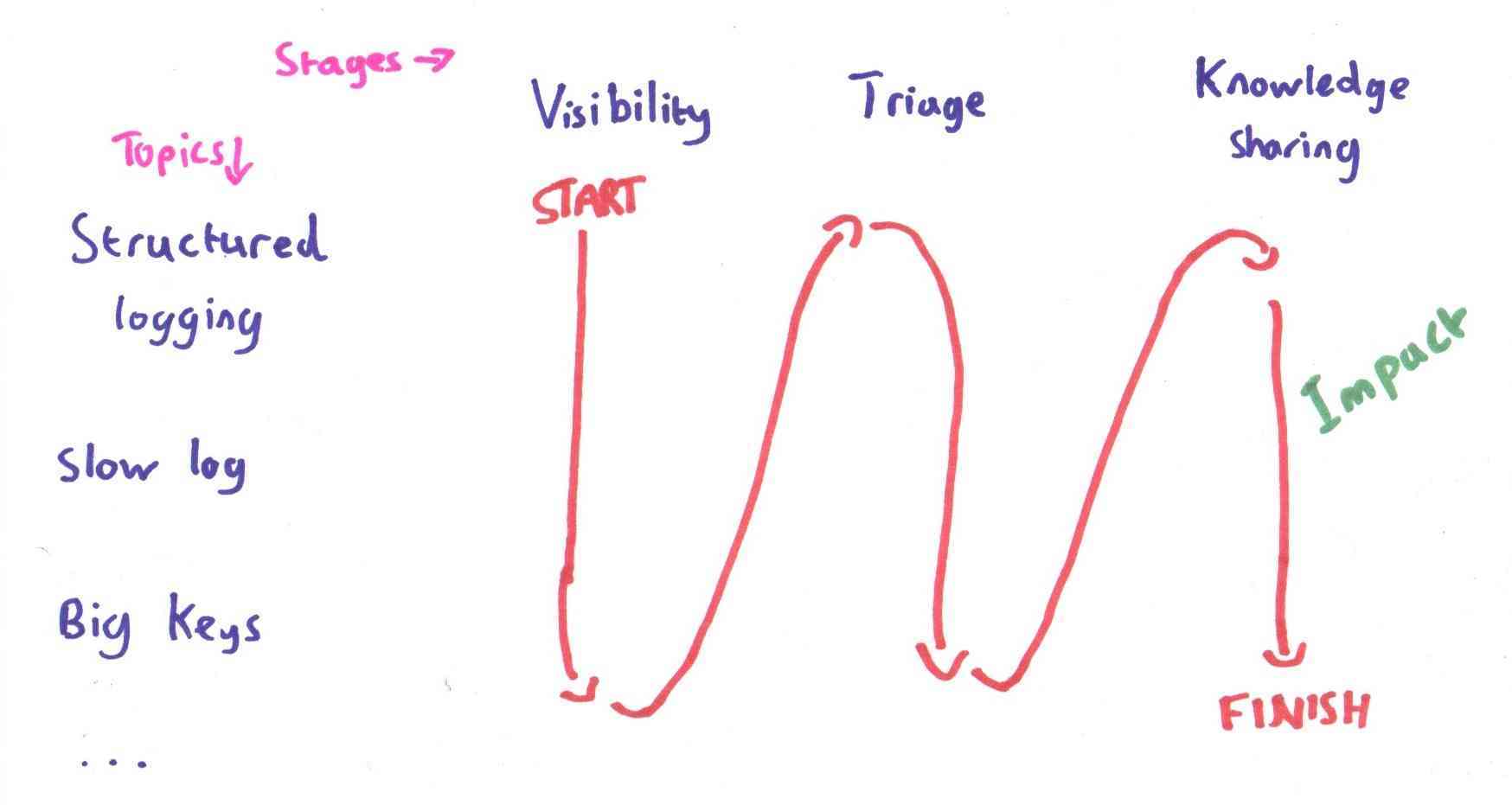
But traveling in the other direction would have been much more
effective:
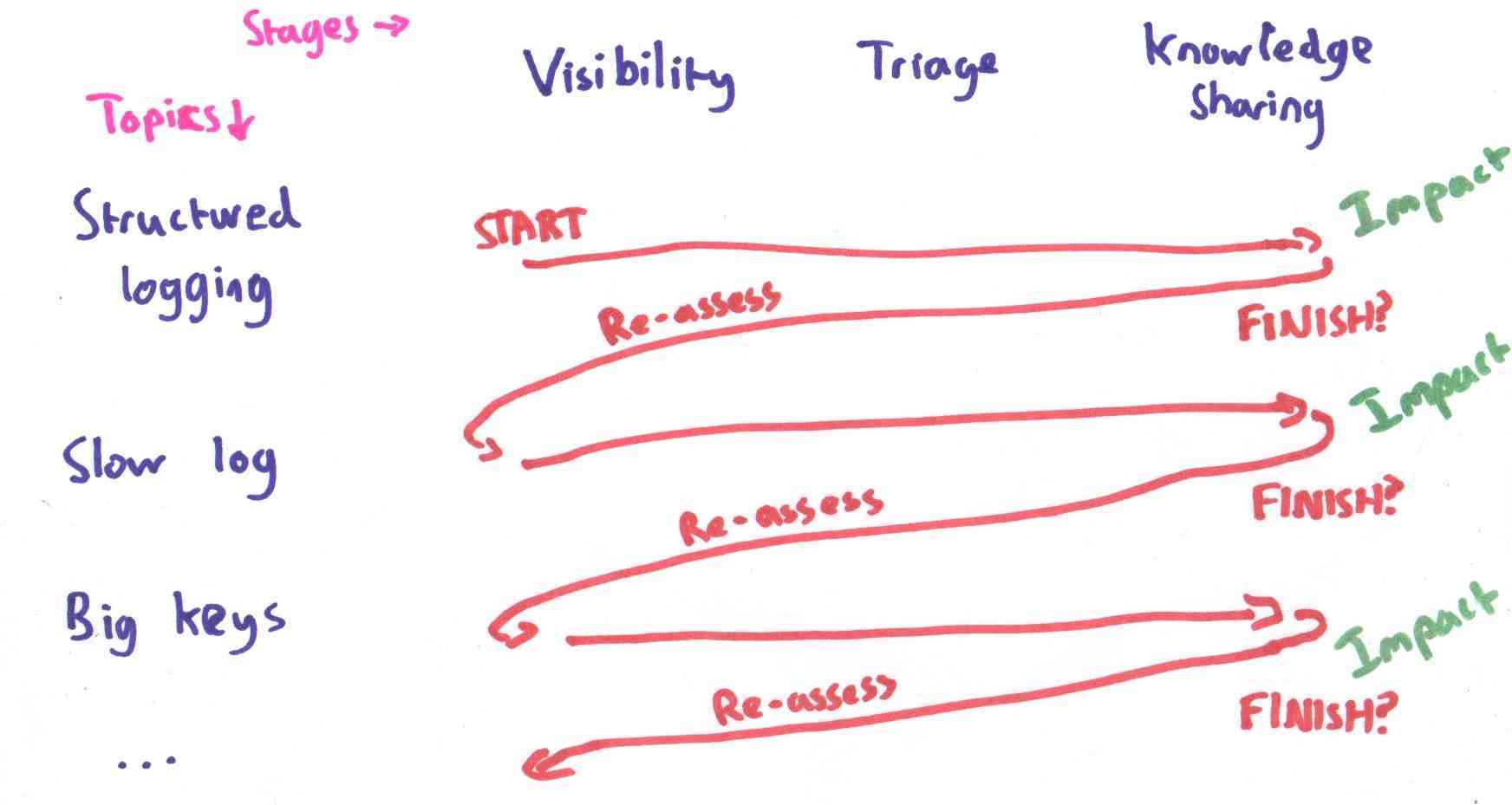
This leads to a state where:
- The impact we make is clearer.
- We start making an impact sooner.
- We can re-assess after every project, and stop early once we have
done enough.
The sooner we have this impact, the sooner we can see the results of
what we've done. It's also good for morale to see these results on a
regular basis!
3. Shape your projects to deliver impact throughout
The way that we originally structured our work to improve Redis usage made it harder to see
our impact than it should have been. For example, we updated our
development documentation at the end of the project.
This was useful, but it would have been much more useful to backend
engineers if we'd updated the documentation along the way, so they always had the best information we could give them.
For a more positive example: in the visibility stage, we created
a couple of issues directly for stage groups to address, rather than
waiting for the triage or knowledge sharing stage to do so. One of those
issues was about large cache entries for merge request
discussions. By getting this in front of the relevant
development team earlier, we were able to
get the fix scheduled and completed sooner as well.
Regularly delivering projects with clear impact means that we get
feedback earlier (from engineers in Development and Infrastructure, or
from the infrastructure itself), we can cover a wider area in less time,
and we are happier about the work we're doing.
As people who went from working directly on user-facing features to
working on a property of the system as a whole, we learned that we can
still set ourselves an MVC to keep us on the right path, as long as we
think carefully about the results we want to achieve.
Cover image by shawn henry on Unsplash


